
In this post, we’ll look at a reactive solution for the Run Length Encoding problem, which is summarized (on Wikipedia) as:
A form of lossless data compression in which runs of data (that is, sequences in which the same data value occurs in many consecutive data elements) are stored as a single data value and count, rather than as the original run.
The challenge here is to perform it in a Reactive way using Reactor operators. Let’s jump in!
update 2018-03-13: Found a few shortcomings of the first implementation and added two new sections that present alternatives.
For the reactive version, we’ll assume that our input is simply a Flux<T> in which some elements can be repeated consecutively.
The desired output could be either:
- a
Stringrepresented the full encoded sequence
or
- a
Flux<Tuple2<T, Long>>representing each encoded run
Since the later can easily enough be transformed to a single String, using reduce, that’s the output we’ll go for.
A first candidate?
Ok so where to start? Maybe there’s an operator that directly fits the bill? Reading the reference documentation’s “Which Operator Do I Need?” appendix,
one close candidate jumps out: distinctUntilChanged. Its javadoc reads:
Filter out subsequent repetitions of an element (that is, if they arrive right after one another).
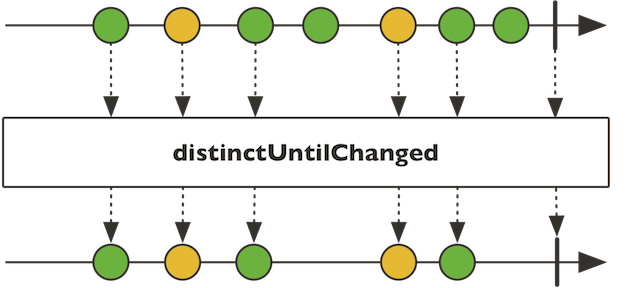
The only problem with that operator is that it eliminates the duplicates, giving us no way of counting how many there were.
Composition to the rescue!
So if there’s no operator that directly solves our use case, the next step should always be to try to find a combination of operators that do. Maybe we need to approach the problem from another angle…
So we need to somehow find runs, sequences of consecutive equal elements within the main sequence.
That sequence-within-a-sequence aspect is interesting: it sounds like we might need to split our original Flux<T> sequence into something that represents the runs.
Two classes of operators can split a Flux in that fashion: operators that buffer and operator that produce windows.
The first one produces Flux<List<T>>, which sounds like a good fit at first: if we get a List<T> for each run, we’ll be able to know its size.
But after a second look it is suboptimal: the List would contain only the same elements, which is redundant.
Furthermore, it would be keeping all equal elements in memory until a different one comes in.
If the source is made up of 1M similar elements, we’ll keep them all in memory 😟
The second class of operators is window, which produces a Flux<Flux<T>>.
The inner Flux<T> (or windows) can be consumed progressively (or rather reactively 😏), and we can apply any Reactor operator to it.
If we could isolate runs as windows, we could reduce the windows to a Tuple2 that contains the duplicate element and the count.
That sounds like a plan!
But let’s come up with the reduce function that will produce the Tuple2 first.
One caveat is that Tuple2 doesn’t allow null (like the majority of Reactor types).
What we can do is require a “neutralElement” value that can be used as the seed as a placeholder for the actual element that is being encoded in that run.
As soon as the first value is emitted in the window, we’ll replace that placeholder by it and start counting:
Flux<T> window = null; //To Be Determined
window.reduce(
//originally no meaningful value in state
//neutralElement needed because null not supported
//maybe a nullable pair custom class would make sense to avoid that
Tuples.of(neutralElement, 0),
//neutralElement is soon replaced by the meaningful value,
//and we increment the associated count
(state, next) -> Tuples.of(next, state.getT2() + 1))
)
Composing window and distinctUntilChanged together
Here comes the hard part: how to split the sequence into run windows?
distinctUntilChanged that we found earlier can help us: we could use it as the trigger for opening new windows, using the window(Publisher) variant.
This variant opens a new window each time the given Publisher emits an element (and also closes the previous window).
There is one caveat still: Reactor Flux can be “cold” ❄️
A cold Publisher is a Publisher that restarts emitting the whole sequence anew for each Subscriber.
The problem of combining window and distinctUntilChanged is that our window opening Publisher needs to be the same as the source of the window, which means 2 subscriptions 😰
So in order for this to work, we need to be able to reuse the source as the window trigger. A ConnectableFlux is probably what we need: publish().refCount(2) is a good candidate.
Here is a generic method that achieves that:
public <T extends Comparable<T>> Flux<Flux<T>> partitionBySameValue(Flux<T> source) {
//in order to make sure the distinctUntilChanged criteria can be applied
//using the same data that we emit in the windows, we need to share...
Flux<T> windowSource = source.publish()
//...between 2 subscribers
.refCount(2);
//partition into windows that are opened whenever the current source element
//differs from the previous source element.
//windows naturally close when a new window opens.
return windowSource.window(windowSource.distinctUntilChanged());
}
And now it is just a matter of processing the run windows using the reduce method we came up with earlier:
public <T> Flux<Tuple2<T, Integer>> runLength(Flux<Flux<T>> partitions,
T neutralElement) {
return partitions
.flatMap(window -> window
.reduce(
Tuples.of(neutralElement, 0),
(state, next) -> Tuples.of(next, state.getT2() + 1)
)
)
//caveat: window produces an empty first window
.filter(t -> t.getT2() > 0);
}
(note the filter that we add due to the operation producing a first window that is empty)
Testing the solution
Let’s create one last method, the one that we discussed at the beginning of this blog, to turn the runLength sequence into an encoded String:
//just reduce the flux of runLength tuples to a single string representation
public <T> Mono<String> string(Flux<Tuple2<T, Integer>> runLength) {
return runLength.reduce("", (s, t) -> s + "," + t.getT1() + "->" + t.getT2())
.map(encoded -> encoded.replaceFirst(",", ""));
}
We chose the VALUE->COUNT comma-separated representation for the purpose of demonstrating this without any ambiguity as to the boundaries of each VALUE and each run representation.
And now we have a generic and reactive run-length encoding method 🎉
As demonstrated by these two tests:
@Test
public void runLengthEncodingIntegers() {
Flux<Integer> source = Flux.just(1, 1, 1, 2, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1);
Flux<Tuple2<Integer, Integer>> runLength = runLength(partitionBySameValue(source), 0);
StepVerifier.create(runLength.as(this::string))
.expectNext("1->3,2->1,3->1,2->2,1->10")
.verifyComplete();
}
@Test
public void runLengthEncodingStrings() {
Flux<String> source = Flux.just("OH", "OH", "OH", "HEY", "Yo", "Yo");
Flux<Tuple2<String, Integer>> runLength = runLength(partitionBySameValue(source), "");
StepVerifier.create(runLength.as(this::string))
.expectNext("OH->3,HEY->1,Yo->2")
.verifyComplete();
}
But there is a problem with how it deals with errors in the source sequence: it is cutting the last run short due to the error:
@Test
public void runLengthEncodingWithError() {
Flux<Integer> source = Flux.just(1, 1, 1, 2, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1)
.concatWith(Mono.error(new IllegalStateException("boom")));
Flux<Tuple2<Integer, Integer>> runLength = runLength(partitionBySameValue(source), 0);
StepVerifier.create(runLength.map(t2 -> t2.getT1() + "->" + t2.getT2()))
.expectNext("1->3","2->1","3->1","2->2","1->10")
.verifyErrorMessage("boom");
}
(note we also removed the string method, since it was also using reduce, failing fast on error)
Maybe we can find an even better implementation?
Preventing errors cutting the last run short
In order to avoid the error-cutting-short issue, we need to suppress the error inside the window.
The main window operator will still notify the flatMap coordinator separately, so we’ll still ultimately be notified of the error.
The Reactor reference guide indicates that the catch-and-swallow imperative pattern can be translated into .onErrorResume(t -> Mono.empty()) in reactive style, so we could try that.
The only problem is that this suppression must be performed mid-reduction, and reduce will unfortunately short-circuit and prevent us from recovering the last intermediate step.
Thinking about intermediate steps could point us in the direction of scan, which is a reduce that also emits intermediate results of the reduction.
We could suppress errors inside the scan and apply takeLast(1) to emit the last available intermediate result (or the final result if everything went well).
Let’s see how this changes our runLength method:
public <T> Flux<Tuple2<T, Integer>> runLength(Flux<Flux<T>> partitions,
T neutralElement) {
return partitions
.flatMap(window -> window
//we use scan and takeLast(1) to keep the state in case of error
.scan(
Tuples.of(neutralElement, 0),
(state, next) -> Tuples.of(next, state.getT2() + 1)
)
//window will also signal the flatMap coordinator, so we must ignore errors here
.onErrorResume(t -> Mono.empty())
//as a result, the last step of the run count reduction is still visible and we can emit it
.takeLast(1)
)
.filter(t -> t.getT2() > 0); // window produces an empty first window
}
However, the solution at this point is getting a bit too convoluted to my taste 😞
My colleague @glynnormington (who first discovered the error issue, kudos) was talking about how it looked like we’d need something similar to Haskell’s takeWhile.
That indeed resonated with me 💡
Using a window variant and per-Subscriber state
Turns out there is a variant of window that resembles takeWhile: windowUntil (note: we also have a takeWhile operator).
In that variant, we provide a Predicate and as soon as it matches, the operator opens a new window.
It can also be configured to include the matching element in the previous window (at the end) or in the new one (at the beginning).
In our case, we’d like to cut the window before the matching value (aka the first element that differs from the current run).
The only thing we need to solve is the state: how to keep track of the current run value?
Having an AtomicReference<T> as state would be a pragmatic solution: despite feeling a bit less clean than with vanilla operators, it would allow for atomic state updates.
But an important principle to follow is not to share the state between subscriptions.
We could create a new AtomicReference<T> state for each subscription by using compose.
This actually allows us to do the windowing AND reduction in one pass, getting rid of the publish and the neutral element in the process 👍
This brings the total amount of code down quite a bit:
public static <T> Flux<Tuple2<T, Integer>> partitionAndRunLength(Flux<T> input) {
return input.compose(source -> {
AtomicReference<T> last = new AtomicReference<>(null);
return source
.windowUntil(i -> !i.equals(last.getAndSet(i)), true) //cutBefore = true
.filter(it -> last.get() != null) //eliminate first empty window
.flatMap(run ->
Mono.just(last.get()) //start tuple with runValue
.zipWith(run
.onErrorResume(t -> Mono.empty()) //suppress inner errors
.count() //count the run length
.map(Number::intValue) //convert it to int
))
});
}
The test now only needs to use partitionAndRunLength:
@Test
public void runLengthEncodingWithError() {
Flux<Integer> source = Flux.just(1, 1, 1, 2, 3, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1)
.concatWith(Mono.error(new IllegalStateException("boom")));
Flux<Tuple2<Integer, Integer>> runLength = partitionAndRunLength(source); //simpler invocation
StepVerifier.create(runLength.map(t2 -> t2.getT1() + "->" + t2.getT2()))
.expectNext("1->3","2->1","3->1","2->2","1->10")
.verifyErrorMessage("boom");
}
And voilà! We solved our problem 🎉
